
Googleが提供する最新の画像生成AIモデル「Gemini 2.0 Flash Experimental」は、ユーザーが自然な言葉で指示するだけで、高品質な画像生成と編集を可能にします。本記事では、このモデルの使い方、可能な操作、そして具体的な活用事例を3つのセクションに分けてご紹介します。
※無料で利用可能です
目次
Gemini 2.0 Flash Experimentalの使い方
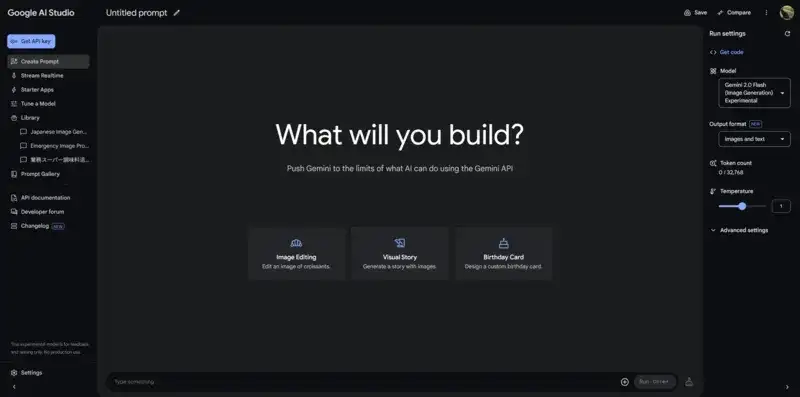
まずは準備から
Gemini 2.0 Flash Experimentalを利用するには、以下の手順を踏みます。
- Google AI Studioへのアクセス: まず、Google AI Studioにアクセスします。
- 左上の「Get API Key」をクリックします
中断にある「APIキーを作成」をクリックします (これで画像の生成ができるようになります) - 左上にある「Google AI Studio」のロゴをクリックして元の画面に戻ります
- モデルの選択: 画面右上の「Model」オプションから「Gemini 2.0 Flash Experimental」を選択します。(デフォルト)
- 出力形式の設定: 「Output Format」を「Images and text」に設定します。(デフォルト)
- 画像のアップロード:下のチャット欄にある⊕ボタンをクリックして 編集したい画像をアップロードします。
- 編集内容の指示: テキストボックスに希望する編集内容を入力し、「Run」ボタンを押すと、指定した編集が適用された画像が生成されます。
例えば、正面向きの人物画像をアップロードし、「back shot」と入力すると、その人物の後ろ姿の画像が生成されます。
日本語でも可能なので、「服を白いシャツに変えて」などでもOKです
Gemini 2.0 Flash Experimentalで可能な操作
このモデルを活用すると、以下のような操作が可能です。
- 画像の生成: テキストプロンプトから高品質な画像を生成できます。
- 画像の編集: 既存の画像に対して、背景の変更、部分的な編集、スタイルの変更などが行えます。
- スタイル変換: 実写画像をアニメ風やイラスト風に変換することが可能です。
- 画像内の要素追加・削除: 特定のオブジェクトや人物を追加・削除することで、画像の内容を自在に編集できます。
これらの操作により、ユーザーは多彩なビジュアルコンテンツを簡単に作成・編集することができます。
ログは残らないので、必要な画像は忘れずに保存してください
Gemini 2.0 Flash Experimentalの活用事例
以下に、具体的な活用事例をいくつかご紹介します。
- プロンプトに画像を追加する: ユーザーがクエリと共に画像を追加することで、Geminiがその画像を分析し、より正確で関連性の高い回答を提供します。
- 動画の要約: YouTubeの動画リンクを入力すると、Geminiが動画の内容を解析し、要約や関連情報を抽出します。
- 手書きメモの要約・解説: 手書きのテキストや図をGeminiにアップロードすることで、その内容を詳しく説明したり、要約としてまとめたりすることが可能です。
これらの活用事例により、Gemini 2.0 Flash Experimentalは、クリエイティブなプロジェクトやビジネス用途でのビジュアルコンテンツ作成を一層効率化することが期待できます。
以上のように、Gemini 2.0 Flash Experimentalは、ユーザーが自然な言葉で指示するだけで、高品質な画像生成と編集を可能にします。その多彩な機能を活用して、さまざまなビジュアルコンテンツを作成してみてはいかがでしょうか。
コメント